The Economy: Recession Forecasting Methodology
Data Collection
All data is collected from FRED, a wealth of economic data compiled and maintained by the Federal Reserve of St. Louis. This was done using an API in R.
To build the model, the data was pulled monthly for variables such as treasury yields, unemployment, consumer sentiment, the Chicago Fed's national financial conditions index, and other variables that I thought would occur simultaneously as or lead a recession. June of 1976 was selected as the starting point for the data because this was how far back the 2-year treasury bill has data for.
After pulling the data, measures that only occur quarterly were filled in on a monthly basis. Spreads between treasury bills were calculated. Changes in values were also calculated for some variables to be used in the model. Finally, offseting the variables (such as a 12 month lead on a treasury yield spread) were joined to the dataset. This was done because the inversion of treasury yield spreads often lead a recession.
Model Building
Many different time periods were used to try to build the model - currently a recession, a recession within 3 months, a recession within 6 months, a recession within a year. All followed the same process but eneded with slightly different configurations of variable importance and hyperparameters. Using the monthly data, hyperparameters were tuned on a gradient boosting machine model. These hyperparameters included the column sample rate, max depth, min rows, min split improvement, and number of trees. The hyperparameters that optimized the model best were selected.
Backtesting was also done on the model to ensure that it was robust to unseen data. To perform this, the model was tested only using data up to August 2004, prior to both the Great Recession that started in 2008 and the recession caused by Covid in 2020. The results of that test compared to using all the data to train on can be seen below.
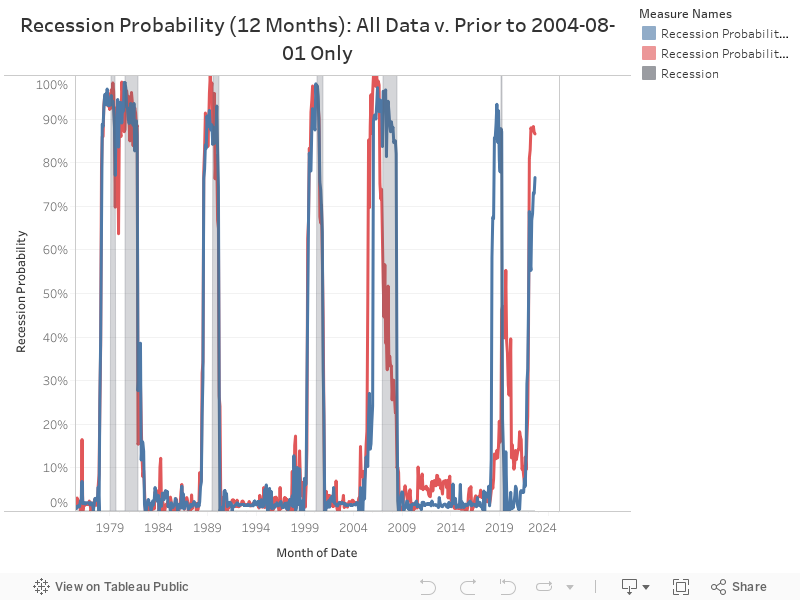
From evaluating performance, the model looked to become more increasingly unstable as the window of predicting a recession becomes smaller. I.e. It is much harder to predict a recession within a 3 month time window compared to a 12 month time window. Because of this, I find it most appropriate to look at the probability of a recession within 12 months, which is a fairly stable model overall. Below, you can see the 20 most important variables in the model to predict a recession within the next 12 months. Unsurprisingly, a lot of them are leading treasury spread variables.

It's important to keep in mind that economists will not even declare there was a recession until after the recession has already occurred. Trying to pinpoint the exact timing of a recession before it even happens is a difficult endevour - much moreso with additional issues that will be discussed below.
Current Model Prediction
The model is run weekly to predict the current probability of a recession. The most recent values for each of the FRED variables are fed into the model. The model is only trained on data a year or older than the current date. This is because economists only determine recessions after the fact. Therefore, FRED will not have a recession indicator until after a recession has occurred, and the recent data should not be used for training.
What Issues Can There Be With the Prediction?
When trying to predict a future event in economics, unknown unknowns typically pose a frightning risk. Economics - especially macroeconomics - is not a science like chemistry or even psychology, where experiments can be run to determine the outcome of a scenario. It would simply be unethical for economists to run experiments to try to create recessions because people's livelihoods depend upon the economy. Therefore, it is often thought there is a rule in economics until it is broken, in which case it is either revised or thrown out altogether. For example, prior to the Financial Crisis that started in late 2007, many banks were bundling risky mortgage loans and selling them to other financial institutions under the premise that the entire US housing market wouldn't collapse at the same time. Up until that point in recent history, it had not. Until it did. Therefore, while the yield curve has been a reliable predictor of recessions in the past, it's important to take pause and think if something might be different this time.
Another challenge of using current data is that the most recent economic data is prone to revisions. When outlets like the Bureau of Labor Statistics puts out its most recent unemployment rate, that is only an estimate. The value can, and most likely will, be revised in the subsequent months. Because of this, the data the model is being built off is actuals while many variables being fed into predicting the current probability of a recession are estimates - that could be revised up or down in the coming months.